Build Insiderオピニオン:岩永信之(7)
次期C#とパフォーマンス向上(後編)―― 予定・検討中の5つの新機構
前編に続き、次期C#のパフォーマンス向上について解説。C# 7以降での採用が予定もしくは検討されているパフォーマンス向上関連の新機能の内容を具体的に見ていこう。
前回は、C#のパフォーマンス向上について、その背景と概要について説明した。現在検討されている機能の一例として以下のようなものがある。
- 参照戻り値
- ローカル関数
ValueTask構造体- スライス(
System.Slices名前空間とSpan構造体) - UTF-8文字列
前編でも説明したが、このうち、参照戻り値とローカル関数は、単純なC#言語構文の追加で、C# 7で実装されそうである。残りの3つは、先にクラスライブラリだけ実装され、その後、関連する言語構文が入りそうで、恐らくC# 7よりもう少し先の話になる。
今回は、これらの新機能についてそれぞれ説明していく。
追加予定・検討中の新機能
参照戻り値
値型を利用することでヒープ確保を避けられる一方で、値型には、変数への代入やメソッドの戻り値に返す際にコピーが発生するという問題がある。
例として、インデックスが任意の数字から始められる非0ベース(non-zero based)な配列を考えてみよう。これまでのC#では、リスト2に示すようなコードになるだろう。
|
struct BasedArray<T>
{
private readonly T[] _data;
public int BaseIndex { get; }
public BasedArray(int baseIndex, int capacity) { BaseIndex = baseIndex; _data = new T[capacity]; }
public T this[int i]
{
get { return _data[i - BaseIndex]; }
set { _data[i - BaseIndex] = value; }
}
}
class Program
{
static void Main()
{
var a = new BasedArray<Point>(0, 3);
//a[0].X = 1;
// ↑これだとエラー。getの戻り値(コピー品)は書き換えられない。
// ↓こう書かないとダメ。
var p = a[0];
p.X = 1; // Xだけ(4byte)書き換えているように見えて
a[0] = p; // Point全体(12byte)の読み書きが発生
}
}
|
Point構造体については前回のリスト1を参照。
コード中のコメントにも書いたが、この実装方法では、Point構造体全体のコピーが発生する。分かりやすくするため図で表すと、図4のようなメモリの使い方になっている。
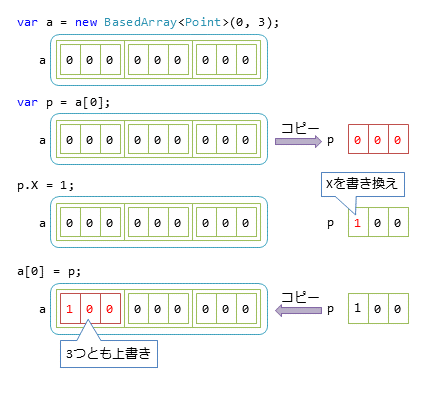
見ての通り、書き換えたいのはX(int型なので4byte)だけなのに、読み書きの両方でPoint型全体(12byte)のコピーが発生する。
このようなコピーのコストは、値型の参照渡しを使えば避けることができる。ただ、現状のC#では、値型の参照渡しを使えるのはメソッドの引数だけである。これは、メソッドの引数であれば参照先が有効であることを保証しやすく、実装が簡単だからである。
一方、コンパイラーがもう少し頑張れば、安全性を損なわずに(=無効な場所を参照しないことを保証しつつ)値型の参照渡しができる箇所がいくつかある。それが、メソッドやプロパティなどの戻り値とローカル変数である。
ちなみに、.NETの仮想マシンレベルでは、最初から戻り値や引数での参照の仕組みを持っている。例えば実は、配列など一部の組み込み型では最初から参照戻り値が使われている。このため、リスト3のようなコードが書ける。
|
class Program
{
static void Main()
{
var a = new Point[3];
// 先ほどの自作のインデクサーと違って、配列はこの書き方ができる。
// 実は、配列のインデクサーの戻り値は参照になっている
a[0].X = 1;
}
}
|
参照を認めていなかったのはあくまでC#のレベルでの制限である。C#に対してパフォーマンスを向上させる要求が高まったのと、コンパイラーをC#で作り直したことで安全性を保証するためのフロー解析がしやすくなったため、制限が緩和されることになった。例えば、リスト2のコードは、C# 7ではリスト4のように書き直すことができる。
|
struct BasedArray<T>
{
private readonly T[] _data;
public int BaseIndex { get; }
public BasedArray(int baseIndex, int capacity) { BaseIndex = baseIndex; _data = new T[capacity]; }
// インデクサーに参照戻り値を使う
public ref T this[int i] => ref _data[i - BaseIndex];
}
class Program
{
static void Main()
{
const int N = 3;
var a = new BasedArray<Point>(0, N);
a[0].X = 1; // OK。配列と同列!
}
}
|
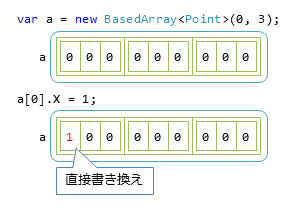
BasedArray型の変更点はインデクサーの実装だけである。戻り値の型(ref T)と、戻り値を返す部分(ref _data[i - Baseindex])にrefキーワードを付けると、参照戻り値が使える。この場合、メモリの使い方は図5のようになり、無駄なコピーが削減できる。
ローカル関数
特定の関数の中からしか使わないような関数を作りたくなることがあるだろう。それを実現するため、関数内に別の関数を書きたくなることがある。
これまでのC#でも、匿名関数(=ラムダ式や匿名メソッド式)を使えば、関数内で関数のようなものを書けた。ただ、以下のような制限がかかっていた。
- 再帰呼び出しが単純にはできない
- イテレーターにできない
そこで、C# 7ではローカル関数という構文を導入する。リスト5に示すような書き方で、「関数内関数」が書ける。
|
using System;
using System.Collections.Generic;
using static System.Console;
class Program
{
static void Main()
{
// ローカル関数で再帰
int f(int n) => n >= 1 ? n * f(n - 1) : 1;
// 5の階乗で120
WriteLine(f(5));
// 1, 2, 3, 4をそれぞれ2倍して、2, 4, 6, 8
WriteLine(string.Join(", ", Double(new[] { 1, 2, 3, 4 })));
}
static IEnumerable<int> Double(IEnumerable<int> source)
{
// イテレーター内でnullチェックを書いても、実際に列挙するまでチェックが働かない
// なので別途nullチェック
if (source == null) throw new ArgumentNullException(nameof(source));
// イテレーター本体を別に用意
// ローカル関数はイテレーターにできる
IEnumerable<int> f()
{
foreach (var x in source)
yield return 2 * x;
}
return f();
}
}
|
匿名関数では面倒だった再帰やイテレーターも書けるという利点の他に、パフォーマンス的にも有利な点がある。ローカル関数であっても、デリゲートへの代入が発生する場合には(※メソッドの引数に渡したり、戻り値として返したりする場合を含む)、匿名関数と同じコードが結果として生成されるが、直接呼び出す場合には、少しパフォーマンスがいいコードが生成されるのだ。
まず、デリゲートを介さないこと自体、パフォーマンス上、有利である。デリゲート型の変数への代入は無駄なヒープ確保を発生させる。ローカル関数は直接呼び出すことで、この無駄なヒープ確保を避けられる。
そしてこの場合、ローカル変数をキャプチャする場合のコードも、表1に示すように、匿名関数の場合と少し異なっている。匿名関数ではコンパイラーによってクラスが生成されて、もともとローカル変数だったものはそのフィールドとして扱われる。ここで、クラスのインスタンスが作られることでヒープが確保される。一方、ローカル関数の場合は、コンパイラーは構造体を作って、ローカル関数に対して参照引数として値を渡す。こうすることでヒープ確保を避けている。
| ローカル関数 | ラムダ式 | |
|---|---|---|
| 元 |
public static void F()
{
int x = 0;
void f(int n) => x = n;
f(10);
Console.WriteLine(x);
}
|
public static void F()
{
int x = 0;
Action<int> f = n => x = n;
f(10);
Console.WriteLine(x);
}
|
| 展開結果 |
public static void F()
{
var s = new FState { x = 0 };
F_f(10, ref s);
Console.WriteLine(s.x);
}
struct FState
{
public int x;
}
static void F_f(int n, ref FState s) => s.x = n;
|
public static void F()
{
var s = new FState { x = 0 };
Action<int> f = s.f;
s.f(10);
Console.WriteLine(s.x);
}
class FState
{
public int x;
public void f(int n) => x = n;
}
|
| 説明 | 構造体の参照渡しを使うことで、ヒープ確保を避けている | 構造体にしても、デリゲートへの代入の時点でボックス化が発生して、ヒープ確保が必要になる。そのため、構造体は使われない |
ValueTask構造体
現状のC#では、非同期メソッドの戻り値はTaskクラス(System.Threading.Tasks名前空間)に限られている。もともと、C# 5.0のプロトタイプ段階では任意の型を戻り値に使える仕組みも検討されていたが、オーバーロード解決やジェネリック型引数の推論との相性が悪く、最終的にはTaskクラスに限ることにしたという背景がある。
しかし、Taskがクラスであることで、無駄なヒープ確保が発生している。例えばリスト6の例を見てほしい。
|
async Task<int> X(Random r)
{
if (r.NextDouble() < 0.5) await Task.Delay(100);
return 1;
}
|
2分の1の確率で遅延を挟んでから値を返すメソッドである。遅延が挟まらなかった場合は同期的に処理が完了する。この場合、完了済みのTaskクラスのインスタンスが作られることになる。このとき、最初から完了済みなのにTaskクラスのインスタンスを作るのは無駄なヒープ確保となる。例えば、リスト7のような、完了済みならただの値を、非同期処理が必要ならTaskクラスを作るような構造体があれば、無駄なヒープ確保を避けられる。
|
struct ValueTask<T>
{
T _result;
Task<T> _task;
public T Result => _task != null ? _task.Result : _result;
public ValueTask(T result) { _result = result; _task = null; }
public ValueTask(Task<T> task) { _result = default(T); _task = task; }
}
|
実際、.NET標準ライブラリにこのようなValueTask構造体が追加される予定である(ソースコードリポジトリ上は実装済み)。
C#の側としても、非同期メソッドの戻り値として任意の型を返せるようにする機能の追加を検討中である。現状では、ValueTask構造体を活用しようとすると非同期メソッドが使えず、リスト8に示すような、古き良き書き方が必要になる。
|
ValueTask<int> X(Random r)
{
if (r.NextDouble() < 0.5)
return new ValueTask<int>(Task.Delay(100).ContinueWith(_ => 1));
else
return new ValueTask<int>(1);
}
|
これは、現状のC#の非同期メソッドがTaskクラス以外の戻り値を認めていないためだ。これに対して、任意の型を非同期メソッドの戻り値に使える構文が検討中である。この構文が入れば、リスト9のような書き方ができる。
|
// 戻り値がTaskクラスではなく、ValueTask構造体
async ValueTask<int> X(Random r)
{
if (r.NextDouble() < 0.5) await Task.Delay(100);
return 1;
}
|
ちなみに、現状のC#がTaskクラス以外の戻り値を認めていないのは、ラムダ式の戻り値の型推論や、オーバーロード解決が難しくなるからである。現在、この問題について、GitHub上でディスカッションが行われている。
スライス
大き目のデータ列の中から、その一部分だけを抜き出して使いたいことがある。例えば、Webでのデータのやりとりを考えてみよう。図6に示すように、ヘッダー情報やさまざまなデータが1つの大きなバイナリ列にシリアライズされて送受信される。

そして、こういう大きなバイナリデータの中から、使いたい部分だけを参照して使いたい場面がある。この要件に対して、現状のC#だと、使いたい部分を別の配列にコピーして使うことになる場面が多く、無駄なヒープ確保が発生していた。
これまでも一応、配列に対してはArraySegment構造体(System名前空間)があった。ただ、以下のような要件に対応できておらず、現状のArraySegment構造体は使いづらくなっている。
- インデクサーの実装がなく、要素の読み書きが面倒
- 配列、
string、ネイティブコードで確保したメモリ領域を統一的に扱いたいが、ArraySegment構造体は配列しか扱えない
そこで、これらの要件を満たしたSpan構造体(System.Slices名前空間)という新しい型の追加が検討されている(現在は試験的な実装がある状態)。
また、この型と関連して、C#にも配列や文字列からSpan構造体を作る専用構文の追加が検討されている。
UTF-8文字列
C#でWebページやWeb APIを作る際に、意外と大きなネックとなるのが文字列のエンコードである。また、C#コンパイラーのコンパイルのパフォーマンスでも、C#ソースコードのエンコードが問題となる。
.NETのstring型は、内部データ的にはUTF-16になっている。1990年代に、2byteの固定長で全ての文字を表せるという幻想の下にUnicodeの仕様策定が進んでいた時代の名残だ。
一方で、現在、文字列エンコード形式としてデファクトスタンダードになっているのはUTF-8である。レガシー資産が絡む場合を除けば、UTF-8以外のエンコード形式を選ぶことはほぼないだろう。
結果として、C#でWebページ・APIを作る際にも、C#コンパイラーがソースコードを読み込む際にも、UTF-8とUTF-16との変換処理が発生することになる。変換が挟まることでCPUもヒープ領域も無駄に浪費するため、これは好ましい状態ではない。
そこで、Utf8String(System.Text.Utf8名前空間)という、UTF-8形式を直接扱うためのクラスが標準ライブラリに追加されそうである(試験的実装あり)。UTF-8にエンコードされたバイト列から直接文字列を読み書きするクラスである。
C#の構文レベルでは、UTF-8文字列リテラルが検討されている。C#ソースコード中に書かれた文字列リテラルは、現状では有無を言わさずstring型(=UTF-16)になってしまい、リテラルからUtf8Stringオブジェクトを作りたい場合、文字エンコードの変換が必要になってしまう。そこで、直接Uft8Stringクラスのインスタンスを作るような構文が必要である。
まとめ
C#は生産性や安全性に重きを置いているが、パフォーマンスへの配慮もそれなりに考えた言語である。しかし、より一層のパフォーマンス向上への余地は残されているし、近年、より良いパフォーマンスを求められる状況がC#にも増えてきた。そこで、C# 7以降ではパフォーマンス向上もテーマの1つとなっている。
今回、そのC#のパフォーマンス向上に関する新機能をいくつか紹介してきた。直接使える場面はそれほど多くなく、使いこなすのも難しいかもしれない。しかし、C#コンパイラー自身や、ASP.NET Coreなどのフレームワークのパフォーマンスが向上することで、多くの開発者に間接的な利益が与えられるだろう。
紹介した機能は総じて、メモリ管理の効率化に関するものである。値型の活用など、不要なヒープ確保を避けることで、GC負担が減り、また、参照局所性が高まり、パフォーマンス向上が期待できる。
岩永 信之(いわなが のぶゆき)

※以下では、本稿の前後を合わせて5回分(第5回~第9回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
6. 次期C#とパフォーマンス向上(前編)―― 必要となった背景と改善内容
機能や構文ばかりが注目されるが、プログラミング言語ではパフォーマンスも重要だ。パフォーマンス向上に対する要求が高まってきた背景と、向上のための改善方法を説明。C# 7以降で追加が検討されている新機能にも言及する。
7. 【現在、表示中】≫ 次期C#とパフォーマンス向上(後編)―― 予定・検討中の5つの新機構
前編に続き、次期C#のパフォーマンス向上について解説。C# 7以降での採用が予定もしくは検討されているパフォーマンス向上関連の新機能の内容を具体的に見ていこう。
8. 見えてきたC# 7: C#の短期リリースサイクル化
C# 7にはどんな新機能が含まれるのかが見えてきた。これまでと比べて、C# 7はかなり速いペースでのリリースとなる。その背景にはどんな事情があるのだろうか。
9. C# 7、そしてその先へ: 非同期処理(前編) - Task-like
C#の進化の中でも「非同期メソッド」はコーディング方法を大きく変えるほど革新的だったが、そこにはまだ課題もある。C# 7~将来のC#で、非同期処理はどう進化するのか、前後編で見ていこう。